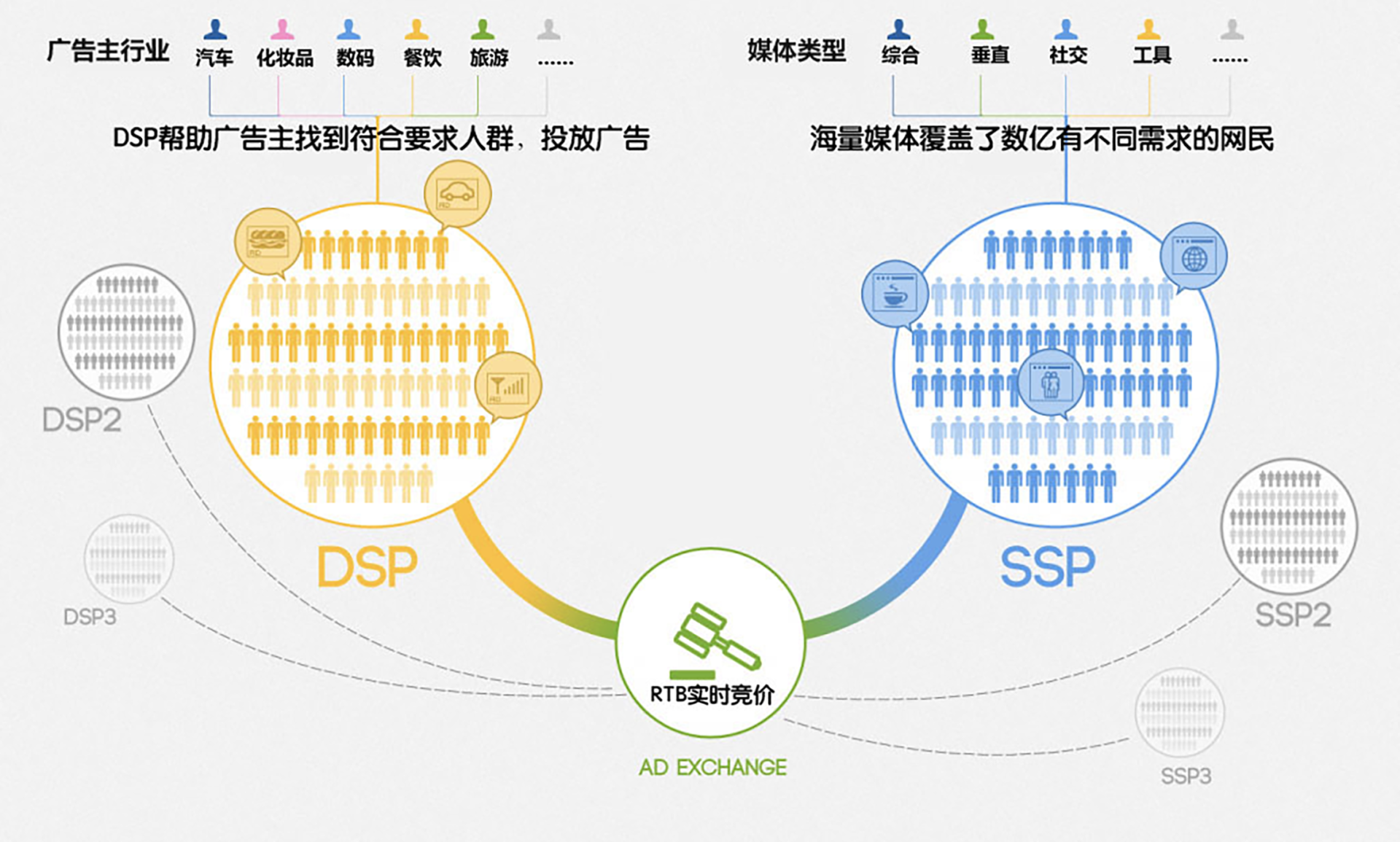
Elasticsearch(简称 ES)是一款基于 Apache Lucene 的分布式搜索和分析引擎。随着业务的发展,系统中的数据量不断增长,传统的关系型数据库在处理大量模糊查询时效率低下。因此,ES 作为一种高效、灵活和可扩展的全文检索解决方案,逐渐成为了企业的首选。本篇博客将深入探讨 Elasticsearch 的核心概念、使用方法以及优化技巧。
为什么要使用Elasticsearch?
系统中的数据,随着业务的发展和时间的推移,将会变得非常多,而业务中往往都是采用模糊查询的方式对数据进行搜索,而模糊查询会导致查询引擎放弃索引,导致系统查询数据的时候都是全表扫描,那么在百万级数据库中,这样的查询效率是非常低下的,而我们使用ES做一个全文索引,将经常查询的系统功能某些字段,比如说电商系统中的商品名,描述和价格这些字段放入到ES索引库中,就可以提高查询效率
并且ES具备以下几个优势
1.高性能:ES具有高性能的搜索和分析能力,其中涵盖了多种查询语言和数据结构
2.可拓展性:ES是分布式的,可以通过增加节点数量去拓展搜索和分析能力
3.灵活性:ES支持多种数据类型,支持多种语言,支持动态映射,允许快速地调整模型以适应不同地需求
4.实时分析:ES支持实时分析,可以对数据进行实时查询,这对于快速检索数据非常有用
5.ES具有可靠性和高可用性,它里面会有冗余备份这样一个设置支持数据备份和恢复。
正排索引与倒排索引
正排索引:类似于关系型数据库的存储方式,它按照文档顺序存储信息,便于按照文档查找内容。
倒排索引:适合全文检索,它记录了每个词条在哪些文档中出现。倒排索引由词条、词典和倒排表构成:
- 词条:最小存储和查询单元。
- 词典:词条的集合,通常实现为 B+ 树或哈希表。
- 倒排表:记录词条出现的文档 ID 列表。
倒排索引的设计使得 ES 能够快速定位和检索相关文档,提高查询效率。
早期的全文检索会为整个文档集合建立一个很大的倒排索引并且将其写入到磁盘,一旦新的索引就绪,旧的索引就会被替代,这样最近的变化就可以被检索到,倒排索引被写入到磁盘后是不可变的,它永远不会被修改,而是用更多的索引,通过增加补充索引的方式去反映新近的修改,而不是直接重写整个倒排索引,每一个倒排索引都会被轮流查询到,从最早的开始的查询,然后再进行合并
ES基本概念:
Near Realtime(NRT)
近实时:当我们说一个系统或数据库是近实时的,它意味着从数据被写入到这些数据可以被检索或查询之间有一个很短的延迟。在Elasticsearch中,这个延迟通常非常短,可能只有几毫秒到几秒(通常不超过1秒)。这意味着,当你向Elasticsearch中写入新的数据后,几乎可以立即查询这些数据,而不需要等待很长时间。
Index(索引)
索引库:你可以把索引库想象成一个巨大的文件柜,里面装满了许多不同类别的文件夹。在Elasticsearch中,这些“文件夹”就是索引,而文件夹里的“文件”就是文档(Documents)。每个索引都包含了一类相似的文档,比如所有的客户数据、商品数据或订单数据都可以分别存储在各自的索引中,一个索引就类似于关系型数据库中的一张表。
Type(类型)
类型:在早期的Elasticsearch版本中,每个索引内可以有多个类型,每个类型下的文档都有相同的字段结构。但随着时间的推移,Elasticsearch团队简化l了这个概念,因为多个类型可能会导致一些复杂性和性能问题。因此,在较新的Elasticsearch版本中,每个索引通常只包含一个类型,但出于兼容性考虑,仍然支持多个类型。但在实际应用中,现在更推荐每个索引只包含一种类型的数据。
Document & Field(文档 & 字段)
文档:在Elasticsearch中,文档是最小的数据单元。你可以把文档想象成一张表格的一行或一个数据库记录。每个文档都是一个JSON对象,包含了多个字段(Field)。
字段:字段就是文档中的一个数据项,比如一个文档可能有一个名为“title”的字段,其值为“The quick brown fox...”。你可以把字段想象成数据库表中的列。每个文档可以有不同的字段组合,但通常同一类型的文档会有相似的字段结构。
映射(Mapping)
mapping是对处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理ES 里面数据的些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射并且需要思考如何建立映射才能对性能更好。
分片(Shards)
可以理解为mysql中的分表,一个索引中的数据太多了需要进行分片,一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有 10 亿文档数据的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力每一份就称之为分片。当你创建一个索引的时候,你可以指定你想要的分片的数量,。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上面去,分片很重要,主要有两方面的原因:
1.允许你水平分割/扩展你的内容容量
2.允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elastigsearch允许你创建分片的一份或多份拷贝这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
1.在分片/节点失败的情况下,提供了高可用性,因为这个原因,注意到复制分片从不与原/主要(origimalprimary)分片置于同一节点上是非常重要的。
2.扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
路由计算/分片控制

分片控制:用户可以访问任何一个节点获取数据,这个节点称为协调节点 ,一般是轮询
模拟写数据:
用户发送请求给ES,但是用户在请求到达ES前是没办法获取到集群状态的,比如说先到达1002节点,但是1002节点可能会把它分发到其他节点上去
1.客户端请求集群节点(任意节点)——协调节点
2.协调节点把请求分发到指定节点
3.主分片需要将数据保存
4.主分片需要将数据发送给副本
5.副本保存后进行反馈
6.主分片进行反馈
7.客户端获取反馈
注意:主分片会要求在活跃的副本到一定数量的时候才进行写操作,为了避免在网络分区故障的时候进行写操作,导致数据不一致问题。
规定数量:int(primary+number_of_replicas)/2)+1
consistency参数的值可以设为one(只要主分片状态ok就允许执行写操作),或者quorum.默认为quorum,就是大多数的分片副本状态没有问题就允许执行写操作。
number_of_replicas指的是在索引设置中设置的副本分片数量,而不是指当前处理活动状态的副本分片数量
读数据

1.客户端首先会发送一个查询请求到协调节点
2.协调节点会计算数据所在的分片以及全部的副本位置
3.为了可以实现负载均衡,可以轮询所有节点
4.协调节点将请求转发给具体的目标节点
5.节点返回查询结果,将结果反馈给客户端
更新流程
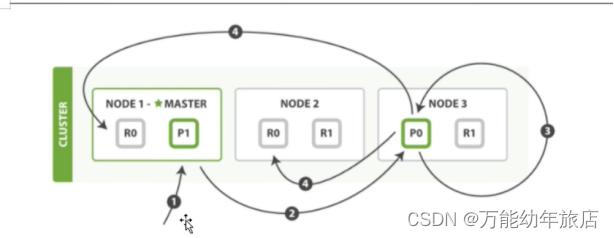
部分更新一个文档的步骤如下:
1.客户端向Node1发送更新请求。
2.将请求转发到主分片所在的Node3
3.Node3从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另外一个线程修改了,就会重试步骤3,超过rety_on_conflict次数后放弃
4.如果Note3成功更新了文档,他将新的版本文档并行转发到Node1和Node2上的副本分配,重新建立索引。一旦所有副本分片都返回成功后,Node3向协调节点也返回成功,协调节点向客户端返回成功。
注意:这里主版本把跟把更改转发到副本分片的时候,不会转发更新请求。相反,他转发的是完整的新版本文档。这些请求会异步的被转发到副本分片,但是不能保证它们按照相同的顺序到达。如果ES采用的是转发更改请求,就有可能会以错误的顺序去把应用更改,导致得到损坏的文档
新增词条
先进入 ES 根目录中的 plugins 文件夹下的ik文件夹,进入 config目录,创建 custom.dic文件,写入新增的词条。同时打开IAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中重启 ES 服务器。
自定义分词器

文档冲突
当我们使用IdnexAPI更新文档的时候,可以一次性读取原始文档,去做我们的修改,然后重新索引整个文档,最近的索引请求将会获胜,不管最后哪一个文档被索引了,都会被唯一存储在ES中。如果其他人同时更改这个索引,那么他们的更改将会丢失。
很多时候这是没有问题的,也许我们的主数据存储是一个关系型数据库,我们只是把数据 复制到了ES中让他可以被检索,也许两个人同时更改相同文档的概率很小,或者对于业务来说偶尔丢失更改并不是很严重的问题,但有时候局部更新出错是不能接受的
怎么防止数据更新丢失呢?
悲观锁
这种方法被关系型数据库广泛使用,它认为冲突必然发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观锁
Elasticsearch 中使用的这种方法假定冲突不是必然发生的,并且不会阻塞正在尝试的操作,然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何作。解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index ,GET 和 delete 请求时,我们指出每个文档都有一个 version(版本)号,当文档被修改时版本号递增。Elasticsearch 使用这个version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
外部系统版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号-或一个能作为版本号的字段值比如 timestamp那么你就可以在 Elasticsearch 中通过增加 version type=extemmal 到查询字符串的方式重用这些相同的版本号, 版本号必须是大于零的整数,且小于 9.2E+18-一个 Java 中 long类型的正值。